
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, Shmargaret Shmitchell *
L’intelligenza artificiale è intelligente? L’analisi tecnica del funzionamento dei modelli linguistici svela cosa abbiamo davanti: nulla più di pappagalli stocastici. Uno studio dall’interno della Silicon Valley
Lanciato a novembre 2022, il chatbot ChatGPT ha acceso il dibattito sulle capacità raggiunte dall’intelligenza artificiale e sulle relative implicazioni sociali e politiche. ChatGPT è di fatto un modello linguistico (LM) di grandi dimensioni, addestrato su set di dati raccolti nel web. Un aspetto ormai noto è la dinamica con cui la IA riproduce pregiudizi, stereotipi e narrazioni dominanti, meno diffusa è la consapevolezza di che cosa siano i modelli linguistici e se, e con quale significato, possano dirsi ‘intelligenti’. È una questione fondamentale per comprendere cosa abbiamo davanti. Lo studio di cui pubblichiamo qui un estratto esce nel marzo 2021 a firma, tra le altre, di Melanie Mitchell – accademica, si occupa di sistemi complessi, intelligenza artificiale e scienze cognitive (qui con lo pseudonimo Shmargaret Shmitchell), ha guidato il team di Google sull’etica nella IA, e la pubblicazione di questo paper le è valso il licenziamento –; lo studio ricostruisce tecnicamente i meccanismi per cui un LM può produrre un testo apparentemente fluido e coerente, ma la macchina che lo genera non ha alcun grado di comprensione: “La nostra percezione del testo in linguaggio naturale, indipendentemente da come è stato generato, è mediata dalla nostra competenza linguistica, e dalla nostra predisposizione a interpretare gli atti comunicativi come veicolanti un significato e un intento coerenti, indipendentemente dal fatto che tali atti lo abbiano. Il problema è che se un lato della comunicazione non ha significato, allora la comprensione del significato implicito è una illusione derivante dalla nostra singolare umana comprensione del linguaggio. Contrariamente a quanto può sembrare quando osserviamo il suo output, un modello linguistico è un sistema per riassemblare insieme in modo casuale sequenze di forme linguistiche che ha osservato nei suoi vasti dati di addestramento, in base a informazioni probabilistiche su come si combinano, ma senza alcun riferimento al significato: un pappagallo stocastico”.
1. INTRODUZIONE
Una delle maggiori tendenze nell’elaborazione del linguaggio naturale (PNL) è stata l’aumento delle dimensioni dei modelli linguistici (Language Models, LM), misurati dal numero di parametri e dalla dimensione dei dati di addestramento. Dal 2018 abbiamo visto l’emergere di BERT (1) e delle sue varianti GPT-2 e GPT-3 (prodotte da OpenAI, rispettivamente nel 2019 e nel 2020, n.d.a.), T-NLG (creato da Microsoft nel 2020, n.d.a.) e, più recentemente, Switch-C (prodotto da Google nel 2021, n.d.a.), con aziende apparentemente in competizione per produrre LM sempre più grandi. Mentre lo studio delle proprietà degli LM e di come cambiano con le dimensioni riveste un interesse scientifico, e i grandi LM hanno mostrato miglioramenti in vari compiti, ci chiediamo se si sia riflettuto a sufficienza sui potenziali rischi associati al loro sviluppo, e sulle strategie per mitigarli.
Consideriamo innanzitutto i rischi ambientali. Facendo eco a una linea di lavoro recente che delinea i costi ambientali e finanziari dei sistemi di deep learning, incoraggiamo la comunità di ricerca a dare la priorità a questi impatti. Un modo per farlo è riportare i costi e valutare i lavori in base alla quantità di risorse che consumano. Come delineiamo nel capitolo 3, l’aumento dei costi ambientali e finanziari di questi modelli punisce doppiamente le comunità emarginate, che hanno meno probabilità di beneficiare dei progressi raggiunti dai grandi LM e maggiori probabilità di essere danneggiate dalle conseguenze ambientali negative del loro consumo di risorse. Vista la dimensione di ciò che stiamo discutendo (delineata nel capitolo 2), la prima considerazione dovrebbe essere il costo ambientale.
Proprio come l’impatto ambientale cresce con le dimensioni del modello, così la difficoltà di capire cosa c’è nei dati di addestramento. Nel capitolo 4 discutiamo di come grandi insiemi di dati basati su testi presi da Internet, sovra-rappresentino punti di vista egemonici e codifichino pregiudizi potenzialmente dannosi per le popolazioni emarginate. Nella raccolta di set di dati sempre più grandi rischiamo di incorrere in debiti di documentazione. Raccomandiamo di mitigare questi rischi mettendo a budget, all’inizio di un progetto, la cura e la documentazione, e creando solo set di dati della dimensione che può renderli sufficientemente documentati.
Come sostenuto da Bender e Koller, è importante comprendere i limiti degli LM e contestualizzare il loro successo. Questo non solo aiuta a ridurre la pubblicità che può fuorviare il pubblico, e gli stessi ricercatori, riguardo alle capacità di questi LM, ma potrebbe incoraggiare nuove direzioni di ricerca, che non dipendono necessariamente dall’avere LM più grandi. Come discutiamo nel capitolo 5, i modelli linguistici non eseguono la comprensione del linguaggio naturale, e hanno successo solo in compiti che possono essere affrontati manipolando la forma linguistica. Concentrarsi sui risultati all’avanguardia nelle classifiche, senza incoraggiare una comprensione più approfondita del meccanismo con cui tali successi vengono raggiunti, può causare risultati fuorvianti, e dirigere le risorse lontano dagli sforzi che faciliterebbero il progresso a lungo termine verso la comprensione del linguaggio naturale, senza utilizzare dati di addestramento insondabili.
Inoltre, la tendenza degli interlocutori umani ad attribuire un significato dove non c’è, può indurre in errore sia i ricercatori di PNL che il pubblico utilizzatore, portati a considerare significativo il testo artificiale. Una situazione che diviene ancora più dannosa in combinazione con la capacità degli LM di contenere, nei dati di addestramento, sia pregiudizi sottili che forme apertamente offensive, linguaggio dispregiativo e una discriminazione che, attraverso interazioni con il linguaggio artificiale, può essere rafforzata all’interno della società. Esploriamo questi potenziali danni nel capitolo 6 e i potenziali percorsi da seguire nel capitolo 7.
Ci auguriamo che una panoramica critica dei rischi insiti nell’affidarsi, come motore principale per l’aumento delle prestazioni della tecnologia linguistica, a dimensioni sempre crescenti di LM, possa facilitare una riallocazione degli sforzi verso approcci che evitino alcuni di questi rischi, pur continuando a raccogliere i benefici dei miglioramenti.
2. BACKGROUND
Con il termine modello linguistico intendiamo fare riferimento a sistemi addestrati su attività di predizione di stringhe: ovvero, sistemi che prevedono la probabilità di un token (carattere, parola o stringa) dato il contesto precedente o, in LM bidirezionali e mascherati, dato il contesto circostante. Tali sistemi non sono supervisionati e, una volta implementati, accettano un testo come input, generando comunemente punteggi o previsioni di stringhe.
Inizialmente proposti da Shannon nel 1949, alcuni dei primi LM risalgono a inizio anni ‘80, e sono stati utilizzati come componenti nei sistemi per il riconoscimento vocale automatico (Automatic Speech Recognition, ASR), per la traduzione automatica (Machine Translation, MT), per la classificazione dei documenti, e altro ancora. In questo capitolo, forniamo una breve panoramica della tendenza generale della modellazione del linguaggio negli ultimi anni. […]
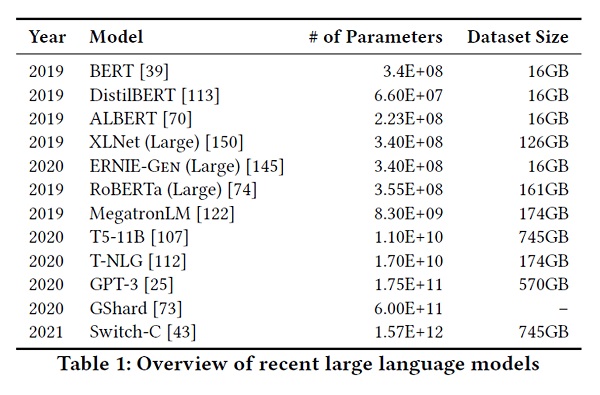
Gli attuali modelli Transformer (2) sono stati in grado di beneficiare di architetture sempre più grandi e di sempre maggiori quantità di dati. […] La Tabella 1 riassume una selezione di questi LM in termini di dimensioni e parametri dei dati di addestramento. Man mano che quantità sempre maggiori di testo vengono raccolte in Internet e riunite in set di dati come Colossal Clean Crawled Corpus e Pile (3), è prevedibile che, fino a quando sarà correlata a un aumento della prestazione, continuerà la tendenza verso LM sempre più grandi. […]
Il passaggio dai primi LM a quelli attuali – dai modelli n-grammi, ai vettori di parole derivati da LM neurali, ai Transformer pre-addestrati di oggi – è accompagnato da un’espansione e da un cambiamento nei tipi di compiti per i quali hanno una utilità. Inizialmente LM n-grammi erano tipicamente impiegati nella selezione degli output, per esempio, di modelli acustici o di traduzione; i vettori di parole derivati da LSTM sono stati rapidamente utilizzati per una varietà di attività di PNL che coinvolgono etichettatura e classificazione, per la loro più efficace ‘rappresentazione’ delle parole (al posto della caratteristica ‘molte parole’); infine, gli attuali modelli Transformer pre-addestrati possono essere ri-addestrati su dataset molto piccoli, per eseguire compiti di apparente manipolazione del significato come fare un riepilogo, rispondere a una domanda e simili (come ChatGPT, n.d.a.). Tuttavia, tutti questi modelli condividono la proprietà di essere LM nel significato che abbiamo dato, ossia sistemi addestrati a prevedere sequenze di parole (o di caratteri o di frasi). Differiscono nella dimensione dei set di dati di addestramento che utilizzano, e nelle sfere di influenza su cui possono eventualmente agire. Questo fa sì che gli attuali LM, molto grandi, incorrano in nuove tipologie di rischio, che analizziamo nei capitolo seguenti.
3. COSTO AMBIENTALE E FINANZIARIO
Strubell et al. (2019) hanno recentemente confrontato i costi di addestramento e sviluppo del modello Transformer in termini di dollari ed emissioni stimate di CO2. Mentre l’essere umano medio è responsabile di circa 5 tonnellate di CO2 per anno, gli autori hanno formato un grande modello Transformer […] e hanno stimato che tale procedura ha emesso 284 tonnellate di CO2. Si stima che l’addestramento di un singolo modello base BERT su GPU (senza messa a punto dell’iperparametro) richieda la stessa energia di un volo transamericano.
Sebbene parte di questa energia provenga da fonti rinnovabili o dall’uso, da parte delle società di cloud computing, di fonti di compensazione dei crediti di carbonio, gli autori osservano che la maggior parte dell’energia dei fornitori di cloud computing non proviene da fonti rinnovabili, e che molte fonti energetiche nel mondo non sono a emissioni zero. Inoltre, le fonti energetiche rinnovabili sono ancora costose per l’ambiente, e i data center con crescenti requisiti di calcolo tolgono energia verde ad altri potenziali usi. Gli autori sottolineano dunque la necessità di modelli di architetture e di paradigmi di addestramento ad alta efficienza energetica.
Strubell et al. esaminano anche il costo dei modelli, rispetto ai loro guadagni in precisione. […] La quantità di calcolo utilizzata per addestrare i più grandi modelli di deep learning (per NLP e altre applicazioni) è aumentata di 300.000 volte in sei anni […].
Quando eseguiamo analisi di rischio/beneficio della tecnologia linguistica, dobbiamo tenere presente il modo in cui i rischi e i benefici sono distribuiti, perché non si accumulano sulle stesse persone. Da un lato, è ben documentato nella letteratura sul razzismo ambientale, che gli effetti negativi del cambiamento climatico stanno raggiungendo e colpendo per prime le comunità più emarginate del mondo. È giusto chiedere, per esempio, che i residenti delle Maldive (probabilmente sott’acqua entro il 2100) o le 800.000 persone in Sudan colpite da drastiche alluvioni, debbano pagare il prezzo ambientale della formazione e del dispiegamento di LM inglesi sempre più grandi, quando simili modelli su larga scala non vengono prodotti per Dhivehi o per l’arabo sudanese?
Mentre alcune tecnologie linguistiche sono realmente progettate per avvantaggiare le comunità emarginate, la maggior parte è costruita per soddisfare le esigenze di coloro che nella società hanno già i maggiori privilegi. Consideriamo, per esempio, chi è probabile abbia le risorse finanziarie per acquistare Google Home, Amazon Alexa o un dispositivo Apple con Siri installato, e abbia anche una buona conoscenza di una lingua che il dispositivo è programmato per utilizzare. Inoltre, quando i grandi LM codificano e rafforzano i pregiudizi egemonici (vedere i capitoli 4 e 6), è più probabile che i danni che ne conseguono ricadano sulle popolazioni emarginate le quali, anche nelle nazioni ricche, hanno maggiori probabilità di sperimentare il razzismo ambientale. […]
È giunto il momento che i ricercatori diano la priorità all’efficienza energetica e ai costi per ridurre l’impatto ambientale negativo e l’accesso iniquo alle risorse, che colpiscono in modo sproporzionato le persone che si trovano già in posizioni emarginate.
4. DATI DI ADDESTRAMENTO INSONDABILI
La dimensione dei dati disponibili sul web, ha consentito ai modelli di deep learning di ottenere un’elevata precisione su benchmark specifici nelle applicazioni di PNL e visione artificiale. Tuttavia, in entrambe le aree di applicazione, i dati di addestramento hanno dimostrato di avere caratteristiche problematiche, creando modelli che codificano associazioni stereotipate e dispregiative di genere, razza, etnia e stato di disabilità. In questo capitolo discutiamo di come grandi dataset, non curati e basati su Internet, codifichino la visione dominante/egemonica che danneggia ulteriormente le persone ai margini, e raccomandiamo un’allocazione significativa delle risorse verso la cura del set di dati e le pratiche di documentazione.
Le dimensioni non garantiscono la diversità
Internet è uno spazio virtuale ampio e diversificato e, di conseguenza, è facile immaginare che set di dati molto grandi, come Common Crawl (“petabyte di dati raccolti in otto anni di web crawling”, una versione filtrata dei quali è inclusa nei dati di addestramento di GPT-3. Vedi nota 3, n.d.a.), sia ampiamente rappresentativo dei modi in cui le diverse persone vedono il mondo. Tuttavia, a un esame più attento, troviamo che ci sono diversi fattori che limitano la partecipazione a Internet, che limitano le discussioni che vengono incluse attraverso la metodologia di crawling e che limitano, infine, i testi che possono essere utilizzati dopo che i dati scansionati sono stati filtrati; in tutti i casi, è anche più probabile che vengano mantenute le voci delle persone che più aderiscono a un punto di vista egemonico. Nell’inglese statunitense e britannico, ciò significa che nei dati di addestramento le opinioni suprematiste bianche, misogine, generazionali ecc. sono sovra-rappresentate, non solo superando la loro prevalenza nella popolazione generale, ma anche facendo sì che i modelli addestrati su questi dataset amplifichino ulteriormente pregiudizi e danni.
A partire da chi contribuisce a queste raccolte di testi su Internet, vediamo che l’accesso stesso al web non è distribuito uniformemente, con il risultato che i dati sovra-rappresentano gli utenti più giovani e quelli dei Paesi sviluppati. Tuttavia, non è solo il web nel suo insieme a essere in questione, ma piuttosto suoi sotto-campioni specifici. Per esempio, i dati di addestramento di GPT-2 provengono dallo scraping di collegamenti in uscita da Reddit, e un sondaggio del 2016 del Pew Internet Research rivela che il 67% degli utenti di Reddit negli Stati Uniti sono uomini, e il 64% di età compresa tra 18 e 29 anni. Allo stesso modo, recenti sondaggi sui wikipediani rilevano che solo l’8,8-15% sono donne o ragazze.
Inoltre, mentre i siti di contenuti generati dagli utenti come Reddit, Twitter e Wikipedia si presentano come aperti e accessibili a chiunque, ci sono fattori strutturali, tra cui pratiche di moderazione, che li rendono meno accoglienti per le popolazioni emarginate. Sono documentati numerosi casi (utilizzando tecniche di etnografia digitale) in cui le persone che hanno ricevuto minacce di morte su Twitter hanno avuto i loro account sospesi, al contrario di quelli che hanno emesso le minacce di morte; inoltre le molestie sono subite da un’ampia gamma di gruppi sovrapposti tra cui vittime di abusi domestici, prostitute, persone trans, persone queer, immigrati, pazienti di medici (dai loro fornitori), persone neurodivergenti e persone visibilmente o mentalmente disabili. Il risultato è che un insieme limitato di sotto-popolazioni può continuare ad aggiungere facilmente dati, condividere i propri pensieri e sviluppare piattaforme che includano le proprie visioni del mondo. […]
Anche se le popolazioni che si sentono sgradite nei siti tradizionali istituiscono diversi forum per la comunicazione, è meno probabile che questi vengano inclusi nei dati di addestramento per i modelli linguistici. Prendiamo, per esempio, gli anziani negli Stati Uniti e nel Regno Unito. Entrambi i gruppi articolano individualmente e collettivamente frame anti-età specificatamente attraverso blog […]. Questi forum contengono ricche discussioni su ciò che costituisce la discriminazione basata sull’età e sui relativi impatti. Tuttavia, una comunità di blog come quella descritta da Lazar et al. è meno probabile che venga trovata e inserita nel set di dati, rispetto ad altri blog che hanno più link in entrata e in uscita.
Infine, l’attuale pratica di filtrare i dataset può attenuare ulteriormente le voci delle persone provenienti da identità emarginate. Il set di addestramento per GPT-3 era una versione filtrata di Common Crawl, sviluppato formando un classificatore per selezionare i documenti più simili a quelli utilizzati nei dati di addestramento di GPT-2 – ovvero documenti linkati da Reddit, più Wikipedia e una raccolta di libri. Mentre, secondo quanto riferito, è stato efficace nel filtrare i documenti che il lavoro precedente aveva definito “incomprensibili”, ciò che non viene misurato (e quindi non si conosce) è quanto altro viene filtrato. Il Colossal Clean Crawled Corpus (vedi nota 3, n.d.a.), utilizzato per addestrare un trilione di parametri LM, viene ripulito, tra l’altro, scartando qualsiasi pagina contenente un termine presente in una lista di circa 400 “parole sporche, cattive, oscene o diversamente cattive”. L’elenco è prevalentemente formato da termini legati al sesso, con una manciata di insulti razzisti e vocaboli relativi alla supremazia bianca (per esempio svastica, potere bianco). Sebbene probabilmente efficace nel rimuovere documenti contenenti pornografia (e gli associati stereotipi problematici codificati nel linguaggio di tali siti) e alcuni tipi di incitamento all’odio, questo approccio indubbiamente attenuerà anche l’influenza degli spazi online costruiti da e per le persone LGBTQ, sopprimendo parole come twink. Se filtriamo il discorso delle popolazioni emarginate, non riusciamo a fornire dati di addestramento che recuperano gli insulti e che descrivano in altro modo, in una luce positiva, le stesse identità emarginate.
Così a ogni passo, dalla partecipazione iniziale ai forum Internet, alla presenza continua, alla raccolta e infine al filtraggio dei dati di addestramento, la pratica corrente privilegia il punto di vista egemonico. Accettando grandi quantità di testo web come ‘rappresentative’ di ‘tutta’ l’umanità, rischiamo di perpetuare punti di vista dominanti, aumentare gli squilibri di potere e replicare ulteriormente la disuguaglianza. […]
Dati statici/Modifica delle visualizzazioni social
Un aspetto centrale della formazione dei movimenti sociali implica l’uso strategico del linguaggio per destabilizzare le narrazioni dominanti, e richiamare l’attenzione su prospettive sociali sotto-rappresentate. I movimenti producono nuove norme, nuovi linguaggio e nuovi modi di comunicare. Questo aggiunge sfide all’implementazione LM, poiché le metodologie che vi dipendono corrono il rischio di un “blocco del valore”, nel quale la tecnologia replica le conoscenze più vecchie e meno inclusive.
Per esempio, il movimento Black Lives Matter ha influenzato la generazione e la modifica di articoli di Wikipedia in modo tale che, con la crescita del movimento, gli articoli che informavano sulle sparatorie di persone di colore hanno aumentato la loro copertura, e sono stati pubblicati con una latenza ridotta. È importante sottolineare che gli articoli che descrivevano le sparatorie passate e gli episodi di brutalità della polizia sono stati creati e aggiornati man mano che venivano scritti gli articoli sui fatti nuovi, mostrando come i movimenti sociali stabiliscano connessioni temporali tra gli eventi, per formare narrazioni coese. Più in generale, Twyman et al. evidenziano come i movimenti influenzino attivamente le inquadrature e le riformulazioni delle narrazioni minoritarie, nel tipo di discorso online che potenzialmente forma i dati che sono alla base degli LM.
Un avvertimento importante è che i movimenti scarsamente documentati, e che non ricevono un’attenzione significativa da parte dei media, non verranno catturati affatto. La copertura mediatica può non coprire eventi di protesta e movimenti sociali, e può distorcere avvenimenti che sfidano il potere statale. Ciò è esemplificato dai media che tendono a ignorare l’attività di protesta pacifica e si concentrano invece su eventi drammatici o violenti, un’ottima occasione per la televisione ma quasi sempre si traducono in una copertura critica. Di conseguenza, i dati alla base degli LM rappresentano in modo errato i movimenti sociali e si allineano in modo sproporzionato con i regimi di potere esistenti. […]
Bias di codifica
È ormai noto che i grandi LM mostrano vari tipi di pregiudizi, comprese associazioni stereotipate o sentimenti negativi nei confronti di gruppi specifici. […] Molti studi concludono che questi problemi riflettono le caratteristiche dei dati di addestramento. […]
Cura, documentazione e responsabilità
In sintesi, LM addestrati su grandi dataset, non curati, statici e provenienti dal web, codificano visioni egemoniche che sono dannose per le popolazioni emarginate. Sottolineiamo quindi la necessità di investire risorse significative nella cura e nella documentazione dei dati di addestramento degli LM. […]
Quando ci affidiamo a set di dati sempre più grandi rischiamo di incorrere nel debito di documentazione, ossia di metterci nella situazione in cui i set di dati sono sia non documentati che troppo grandi per essere documentati a posteriori. Mentre la documentazione consente una potenziale responsabilità, i dati di addestramento non documentati perpetuano il danno senza ricorso. Senza documentazione non è possibile cercare di comprendere le caratteristiche dei dati di addestramento, al fine di mitigare alcuni dei problemi evidenziati o addirittura altri, sconosciuti. La soluzione, proponiamo, è quella di preventivare la documentazione come parte dei costi pianificati per la creazione del set di dati, e raccogliere solo la quantità di dati che può essere accuratamente documentata all’interno di tale budget.
[…]
6. PAPPAGALLI STOCASTICI
Qui esploriamo i modi in cui i fattori esposti nei capitoli 4 e 5 – la tendenza dei dati di addestramento ingeriti da Internet a codificare visioni del mondo egemoniche, la tendenza di LM ad amplificare pregiudizi e altri problemi nei dati di addestramento, e la tendenza dei ricercatori e di altre persone a confondere i miglioramenti delle prestazioni degli LM con l’effettiva comprensione del linguaggio naturale – presentano rischi di danni nel mondo reale. Dopo aver esplorato alcuni motivi per cui gli esseri umani confondono l’output LM con un testo significativo, passiamo ai rischi e ai danni derivanti dall’implementazione di un tale modello su larga scala. Scopriamo che il mix di pregiudizi umani e linguaggio apparentemente coerente aumenta il potenziale di bias di automazione, l’uso improprio deliberato e l’amplificazione di una visione del mondo egemonica. Ci concentriamo principalmente sui casi in cui LM vengono utilizzati per generare testo, ma parleremo anche dei rischi che si presentano quando LM o word embeddings da esse derivati sono componenti di sistemi per la classificazione, per l’espansione di query o di altri compiti, o quando gli utenti possono interrogare LM per ottenere informazioni memorizzate dai loro dati di addestramento.
Coerenza nell’occhio di chi guarda
Laddove i tradizionali LM a n-grammi possono solo modellare dipendenze relativamente locali, prevedendo ogni parola data la precedente sequenza di N parole (di solito 5 o meno), i Transformer catturano finestre molto più grandi, e possono produrre un testo apparentemente non solo fluente, ma anche coerente tra i diversi paragrafi. Per esempio, McGuffie e Newhouse hanno interrogato GPT-3 con il testo [sottolineato] nella Figura 2, e GPT-3 ha prodotto il resto del testo, incluso il formato domanda/risposta. Questo esempio illustra la capacità di GPT-3 di produrre testo coerente e in tema; l’argomento è collegato allo studio di McGuffie e Newhouse su GPT-3 nel contesto dell’estremismo […].

Noi diciamo apparentemente coerente, perché la coerenza è negli occhi di chi guarda. La comprensione umana della coerenza deriva infatti dalla nostra capacità di riconoscere le credenze e le intenzioni degli interlocutori, all’interno del contesto. Ossia, l’uso del linguaggio umano ha luogo tra individui che condividono un terreno comune, e sono reciprocamente consapevoli della condivisione (e della sua portata); tra individui che hanno intenti comunicativi, che usano il linguaggio per trasmetterli e che mentre comunicano modellano gli stati mentali reciproci. In quanto tale, la comunicazione umana si basa sull’interpretazione del significato implicito trasmesso tra individui. Il fatto che la comunicazione uomo-uomo sia un’attività costruita congiuntamente, è più chiaramente vero nella comunicazione parlata o co-situata, ma usiamo le stesse strutture per produrre un linguaggio destinato a un pubblico non co-presente con noi (lettori, ascoltatori, osservatori a distanza nel tempo o nello spazio) e nell’interpretazione di tale linguaggio quando lo incontriamo. Ne consegue che anche quando non conosciamo le persone che hanno generato la lingua che stiamo interpretando, costruiamo un modello parziale di chi sono e dei punti in comune che pensiamo condividano con noi, e lo usiamo per interpretare le loro parole.
Il testo generato da un LM non è fondato sull’intento comunicativo, su alcun modello del mondo o su alcun modello dello stato mentale del lettore. Non può esserlo, perché i dati di addestramento non hanno mai incluso la condivisione di pensieri con un ascoltatore, né la macchina ha la capacità di farlo. Ciò può sembrare controintuitivo date le qualità sempre più fluide del testo generato automaticamente, ma dobbiamo tenere conto del fatto che la nostra percezione del testo in linguaggio naturale, indipendentemente da come è stato generato, è mediata dalla nostra competenza linguistica, e dalla nostra predisposizione a interpretare gli atti comunicativi come veicolanti un significato e un intento coerenti, indipendentemente dal fatto che tali atti lo abbiano. Il problema è che se un lato della comunicazione non ha significato, allora la comprensione del significato implicito è un’illusione derivante dalla nostra singolare umana comprensione del linguaggio. Contrariamente a quanto può sembrare quando osserviamo il suo output, un LM è un sistema per riassemblare insieme in modo casuale sequenze di forme linguistiche che ha osservato nei suoi vasti dati di addestramento, in base a informazioni probabilistiche su come si combinano, ma senza alcun riferimento al significato: un pappagallo stocastico.
Rischi e danni
La fluidità e la coerenza del surrogato LM solleva diversi rischi, proprio perché gli esseri umani sono preparati a interpretare le stringhe appartenenti alle lingue che parlano come significative, e corrispondenti all’intento comunicativo di qualche individuo o gruppo di individui, che hanno la responsabilità di ciò che viene detto. Passiamo ora agli esempi, esponendo successivamente i potenziali danni.
I primi rischi che consideriamo sono quelli che derivano dal fatto che LM assorbano la visione egemonica del mondo dai loro dati di addestramento. Quando gli esseri umani producono il linguaggio, le nostre espressioni riflettono le nostre visioni del mondo, compresi i nostri pregiudizi. Poiché le persone in posizioni di privilegio rispetto al razzismo, alla misoginia, all’abilismo ecc. tendono a essere sovra-rappresentate nei dati di addestramento per LM (come discusso nel capitolo 4), questi dati includono di conseguenza pregiudizi codificati, molti già riconosciuti come dannosi. […] Mentre alcune delle parole più apertamente dispregiative potrebbero essere filtrate, non tutte le forme di abuso online sono facilmente rilevabili utilizzando le parole tabù […]. Un LM addestrato su tali dati raccoglierà questo tipo di associazioni problematiche. Se esso produce un testo che viene generato affinché le persone lo interpretino (contrassegnato come prodotto da una IA o altro), quali rischi ne derivano? In primo luogo, prevediamo che LM che producono testo riproducano e persino amplifichino i bias nei loro input. Quindi il rischio è che le persone diffondano il testo generato da LM, il che significa più testo disponibile nel mondo che rafforza e propaga stereotipi e associazioni problematiche, sia agli umani che ai futuri LM formati su set di addestramento che hanno ingerito l’output della precedente generazione di LM. […]
Una terza categoria di rischio coinvolge i cattivi attori che sfruttano la capacità dei grandi LM di produrre su richiesta grandi quantità di testi apparentemente coerenti su argomenti specifici, senza avere alcun interesse nella verità del testo generato. Possono esserci casi prosaici, come servizi impostati per scrivere ‘automaticamente’ tesine o interagire sui social media, nonché casi d’uso legati alla promozione dell’estremismo. […]
Un altro rischio coinvolge la traduzione automatica (MT), e il modo in cui una maggiore fluidità dell’output cambia l’adeguatezza percepita dell’output stesso. È diverso dai casi precedenti, in quanto vi è un iniziale intento comunicativo umano, da parte dell’autore del testo nella lingua di partenza; tuttavia, i sistemi MT possono (e spesso lo fanno) produrre un output impreciso ma fluente e (di nuovo, apparentemente) coerente di per sé, per un utente che non vede il testo originale o non è in grado di comprenderlo da solo; e quando egli scambia il significato attribuito all’output MT come l’effettivo intento comunicativo dell’autore del testo originale, può derivarne un danno reale. […]
Notiamo che i rischi associati a un testo artificiale, ma apparentemente coerente, sono profondamente connessi al fatto che tale testo può entrare nelle conversazioni senza che alcuna persona o entità ne sia responsabile. Una responsabilità che implica la veridicità, aspetto importante per situare il significato. Come scrive Maggie Nelson: “Le parole cambiano a seconda di chi le pronuncia; non esiste cura”.
[…]
8. CONCLUSIONE
Gli ultimi anni, da quando la capacità di elaborazione ha raggiunto i modelli neurali, sono stati tempi esaltanti nel mondo della PNL. Gli approcci neurali in generale, e in particolare i grandi Transformer LM, hanno rapidamente superato le classifiche su un’ampia varietà di benchmark, e ancora una volta l’adagio “there’s no data like more data”, appare vero. Può sembrare che il progresso nel settore, infatti, dipenda dalla creazione di modelli linguistici sempre più grandi (e dalla ricerca su come utilizzarli a vari fini).
In questo documento, abbiamo invitato i lettori a fare un passo indietro e a chiedersi: sono inevitabili o necessari LM sempre più grandi? Quali costi sono associati a questa direzione di ricerca, e cosa dovremmo considerare prima di intraprenderla? Il campo della PNL o il pubblico che serve hanno effettivamente bisogno di LM più grandi? Se sì, come possiamo perseguire questa direzione della ricerca mitigando i rischi associati? Se no, di cosa abbiamo invece bisogno?
Abbiamo identificato un’ampia varietà di costi e rischi associati alla corsa per LM sempre più grandi, tra cui: costi ambientali (generalmente sostenuti da coloro che non beneficiano della tecnologia risultante); costi finanziari, che a loro volta erigono barriere all’ingresso, limitando chi può contribuire a quest’area di ricerca, e le lingue che possono beneficiare delle tecniche più avanzate; costi di opportunità, poiché i ricercatori dedicano sforzi a direzioni che richiedono meno risorse; e il rischio di danni sostanziali, inclusi stereotipi, denigrazione, aumento dell’ideologia estremista e arresto illegale, se gli esseri umani incontrano un output LM apparentemente coerente e lo prendono per le parole di qualche persona o organizzazione che ha la responsabilità di ciò che viene detto.
Pertanto, invitiamo i ricercatori della PNL a soppesare attentamente questi rischi mentre perseguono questa direzione di ricerca, a considerare se i benefici superano i rischi, e a indagare gli scenari di doppio uso utilizzando le molte tecniche qui proposte […].
* Estratto (traduzione a cura di Paginauno) dal paper On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?, Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, Shmargaret Shmitchell. FAccT ‘21: 2021 ACM Conference on Fairness, Accountability, and Transparency Virtual Event Canada March 3-10, 2021. La versione integrale, in inglese, sotto Creative Commos, con note e bibliografia, qui https://dl.acm.org/doi/10.1145/3442188.3445922
1) Bidirectional Encoder Representations from Transformers (BERT) è un modello di machine learning utilizzato nell’elaborazione del linguaggio naturale; è stato creato da Google, che nel 2019 ha annunciato di aver iniziato a utilizzarlo per il suo motore di ricerca. Nota di redazione
2) Il Transformer è un modello linguistico che può essere addestrato a leggere molte parole (una frase o un paragrafo, per esempio), a prestare attenzione a come queste parole si relazionano l’una con l’altra, e quindi a prevedere quali parole possono seguire. Nota di redazione
3) Common Crawl è un’organizzazione senza scopo di lucro che esegue periodicamente la scansione del web e rende gratuitamente disponibili i propri archivi e set di dati; Colossal Clean Crawled Corpus è un set di dati creato applicando una serie di filtri a una singola scansione di Common Crawl – filtri atti a escludere dati discriminatori, offensivi ecc. ma che, come mostra questo studio, non sono affatto sufficienti per costruire un dataset di addestramento privo di pregiudizi, bias ecc. –; anche OpenAI ha usato una versione filtrata di Common Crawl per addestrare il modello linguistico di GPT-3. Anche Pile è un dataset per modelli linguistici. Nota di redazione
