Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, Ross Anderson
Modelli AI che si addestrano su dati raccolti in rete generati da precedenti modelli AI: uno studio mostra come il conseguente ‘collasso del modello’ porterà a distorsioni della realtà
“Fino a oggi, la maggior parte del testo online è stato scritto da esseri umani. Ma questo testo è stato usato per addestrare GPT-3 e GPT-4, che sono apparsi come assistenti di scrittura nei nostri strumenti di editing. Quindi sempre più testo sarà scritto da grandi modelli linguistici (LLM). Dove porta tutto questo? Cosa succederà a GPT-{n} quando gli LLM contribuiranno alla maggior parte del linguaggio trovato online?” Se lo domanda Ross Anderson, professore di security engineering all’Università di Cambridge e all’Università di Edimburgo, sul suo blog (1), e continua: “E non si tratta solo di testo. Se si addestra un modello musicale su Mozart, ci si può aspettare un risultato che assomiglia un po’ a Mozart ma senza la sua brillantezza – chiamiamolo ‘Salieri’. E se Salieri addestra la generazione successiva, e così via, come suonerà la quinta o la sesta generazione?”
Anderson è uno degli autori del paper The Curse of Recursion: Training on Generated Data Makes Models Forget pubblicato il 27 maggio scorso nell’archivio open access ArXiv (2). E sottolinea nel suo blog: “Nel nostro ultimo lavoro, dimostriamo che l’utilizzo nell’addestramento di contenuti generati da un modello precedente provoca difetti irreversibili. Le code della distribuzione originale dei contenuti scompaiono. Nel giro di poche generazioni, il testo diventa spazzatura, poiché le distribuzioni gaussiane convergono e possono persino diventare funzioni delta. Chiamiamo questo effetto model collapse (collasso del modello). Così come abbiamo disseminato gli oceani di rifiuti di plastica e riempito l’atmosfera di anidride carbonica, stiamo per riempire Internet di blah. […] Dopo aver pubblicato questo articolo, abbiamo notato che Ted Chiang aveva già commentato l’effetto a febbraio, osservando che ChatGPT è come una jpeg sfocata di tutto il testo presente su Internet, e che le copie delle copie peggiorano. Nel nostro articolo analizziamo la matematica, spieghiamo l’effetto in dettaglio e dimostriamo che è universale”.
Un secondo autore del paper, Ilia Shumailov, dell’Università di Oxford, dichiara a Venture Beat (3): “Nel tempo, gli errori nei dati generati dagli LLM si sommano, e alla fine costringono i modelli successivi, addestrati su quei dati, a percepire ulteriormente la realtà in modo errato. Siamo rimasti sorpresi nell’osservare la rapidità con cui avviene il collasso del modello: i modelli possono dimenticare rapidamente la maggior parte dei dati originali da cui hanno appreso inizialmente”. Dati generati dagli esseri umani e che secondo Shumailov “rappresentano il mondo in modo più equo, cioè contengono anche dati improbabili. I modelli generativi, invece, tendono a riprodurre eccessivamente (overfit) i dati più popolari e spesso fraintendono i dati meno popolari”.
Nell’esempio riportato da Shumailov, un modello di apprendimento automatico viene addestrato su un set di dati con immagini di 100 gatti, 10 dei quali con il pelo blu e 90 con il pelo giallo. Il modello apprende che i gatti gialli sono più diffusi, ma rappresenta anche i gatti blu come più giallastri di quanto non siano in realtà, restituendo alcuni risultati di gatto verde quando viene chiesto di produrre nuovi dati. Nel corso del tempo, il tratto originale della pelliccia blu si erode attraverso successivi cicli di addestramento, passando dal blu al verdastro e infine al giallo: questa distorsione progressiva e l’eventuale perdita delle caratteristiche dei dati di minoranza è il ‘collasso del modello’. Non si tratta del fenomeno, già conosciuto in letteratura, sottolineano Shumailov e lo stesso paper, della “dimenticanza catastrofica”, nel quale i modelli perdono informazioni apprese in precedenza: il model collapse riguarda modelli che interpretano erroneamente la realtà sulla base delle loro convinzioni rafforzate.
Il paper è estremamente tecnico, basandosi su analisi matematiche, ne riportiamo qui un estratto dei passaggi più semplici.
The Curse of Recursion: Training on Generated Data Makes Models Forget
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, Ross Anderson
1. Introduzione
Molte comunicazioni umane avvengono online. Miliardi di email vengono scambiate ogni giorno, insieme a miliardi di messaggi sui social media e milioni di articoli di notizie. Quasi tutto questo materiale è stato prodotto e curato solo da esseri umani nei primi anni del world wide web, eppure dall’inizio del secolo i motori di ricerca sono arrivati a determinare ciò che le persone possono trovare, e negli ultimi dieci anni smart editor di testo, lavorando su ortografia e correzione grammaticale, hanno contribuito a modificare ciò che produciamo. Ora, il testo non solo può essere curato e analizzato in modo efficiente; può anche essere generato – da modelli linguistici di grandi dimensioni (Large Language Model, LLM). Questi modelli adesso (probabilmente) superano una forma più debole del test di Turing, nel senso che il loro output non può essere distinto in modo affidabile dal testo scritto da esseri umani.
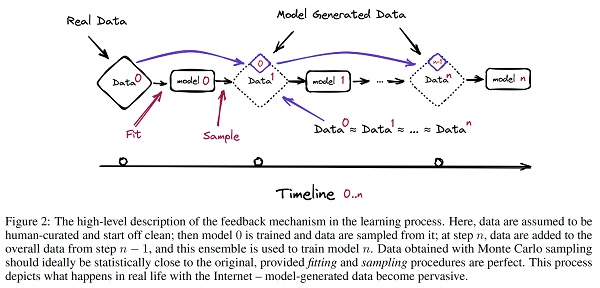
Lo sviluppo di LLM è piuttosto complesso e richiede masse di dati di addestramento. Aneddoticamente, alcuni potenti modelli recenti vengono addestrati utilizzando frammenti di gran parte di Internet, quindi ulteriormente perfezionati con l’apprendimento per rinforzo da feedback umano (RLHF). Un passaggio che aumenta ulteriormente la dimensione effettiva del set di dati. Tuttavia, mentre gli attuali LLM, incluso GPT-4, sono stati addestrati su testo prevalentemente generato dall’uomo, in futuro potrebbe cambiare. Se la maggior parte dei dati di addestramento dei prossimi modelli sarà anch’essa prelevata dal web, allora inevitabilmente i modelli si addestreranno sui dati prodotti dai loro predecessori. In questo studio, esaminiamo cosa succede quando il testo prodotto, per esempio da una versione di GPT, costituisce la maggior parte del set di dati di addestramento dei modelli successivi. Cosa succede alle versioni {n} di GPT, e all’aumentare della generazione {n}? Questa situazione non è limitata ai modelli di testo; si può anche considerare cosa accade quando la musica creata da compositori umani, e suonata da musicisti umani, addestra modelli il cui output addestra altri modelli.
Scopriamo che l’apprendimento dai dati prodotti da altri modelli provoca il “collasso del modello” (model collapse), un processo degenerativo per cui, nel tempo, i modelli dimenticano l’originale distribuzione dei dati sottostanti, anche in assenza di uno spostamento nella distribuzione nel tempo. Forniamo esempi di collasso del modello per Gaussian Mixture Models (GMM), Variational Autoencoders (VAE) e Large Language Models (LLM). Mostriamo che ciò avviene prima con la scomparsa delle code, e nel corso delle generazioni i comportamenti appresi iniziano a convergere verso una stima puntuale con una varianza molto piccola. Inoltre, dimostriamo che questo processo è inevitabile, anche per i casi con condizioni quasi ideali per l’apprendimento a lungo termine, cioè nessun errore di stima della funzione.
Infine, discutiamo le implicazioni più ampie del collasso del modello. Notiamo che l’accesso alla distribuzione originale dei dati è cruciale: per sapere dove contano le code della distribuzione sottostante, è necessario accedere a dati reali prodotti dall’uomo. In altre parole, l’uso di LLM su larga scala per pubblicare contenuti su Internet inquinerà la raccolta di dati per addestrarli: i dati sulle interazioni umane con LLM saranno sempre più preziosi. […]
In questo lavoro diamo i seguenti contributi:
- dimostriamo l’esistenza di un processo degenerativo nell’apprendimento e lo chiamiamo collasso del modello;
- dimostriamo che il collasso del modello esiste in una varietà di diversi tipi di modelli e set di dati;
- dimostriamo che, per evitare il collasso del modello, è essenziale l’accesso a contenuti genuini generati dall’uomo.
[…]
3. Che cos’è il collasso del modello?
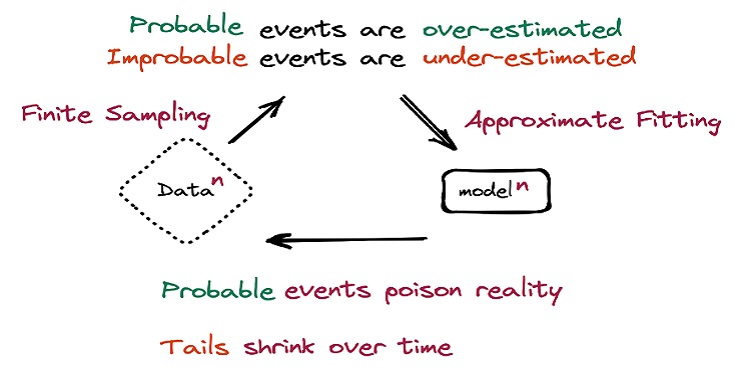
Definizione: il model collapse è un processo degenerativo che interessa generazioni di modelli generativi di apprendimento, in cui i dati finiscono per inquinare il set di addestramento della generazione successiva del modello; essendo addestrati su dati inquinati, percepiscono male la realtà. Identifichiamo due casi: il ‘collasso precoce del modello’ e il ‘collasso tardivo del modello’. Nel primo, il modello inizia a perdere informazioni sulle code della distribuzione; nel secondo, il modello intreccia diverse modalità delle distribuzioni originali e converge in una distribuzione che ha poca somiglianza con quella originale, spesso con una varianza molto piccola.
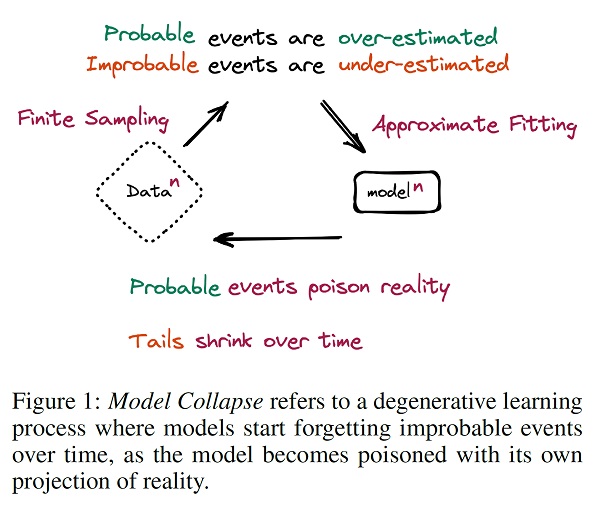
Si noti che questo processo è diverso da quello conosciuto come “dimenticanza catastrofica”, in quanto stiamo considerando più modelli nel tempo e modelli che non dimenticano i dati appresi in precedenza, ma piuttosto iniziano a interpretare erroneamente ciò che credono sia reale, rafforzando le proprie convinzioni.
Questo processo si verifica a causa di due specifiche fonti di errore, che si accumulano nel corso delle generazioni e causano deviazioni dal modello originale; una di esse gioca un ruolo primario e, in sua assenza, il processo non si verificherebbe oltre la prima generazione.
3.1 Cause del collasso del modello
Ci sono due cause principali per il collasso del modello, una primaria e una secondaria, che descriviamo ora. Ulteriori intuizioni matematiche sono fornite nella Sezione 4, per spiegare come esse diano origine agli errori osservati, come le diverse fonti possono combinarsi, e come possiamo quantificare il tasso medio di divergenza del modello.
Errore di approssimazione statistica: è l’errore principale, che sorge a causa del fatto che il numero di campioni è finito e scompare quando il numero di campioni tende all’infinito. Ciò si verifica a causa di una probabilità diversa da zero che le informazioni possano perdersi in ogni fase del ricampionamento. […]
Errore di approssimazione funzionale: è l’errore di tipo secondario, che deriva dal fatto che i nostri approssimatori di funzione sono insufficientemente espressivi (o talvolta troppo espressivi al di fuori del supporto di distribuzione originale). È noto che le reti neurali sono approssimatori funzionali universali al limite, ma in pratica ciò non è sempre vero. In particolare, una rete neurale può introdurre verosimiglianza diversa da zero al di fuori del supporto della distribuzione originale. Un semplice esempio di questo errore è se provassimo ad adattare una combinazione di due gaussiane con una singola gaussiana. Anche se disponiamo di informazioni perfette sulla distribuzione dei dati, gli errori del modello saranno inevitabili. È importante notare anche che in assenza di errore statistico, l’errore di approssimazione funzionale si verifica solo alla prima generazione. Una volta che la nuova distribuzione appartiene all’immagine dell’approssimatore funzionale, rimane esattamente la stessa nel corso delle generazioni.
[…]
6. Discussione e conclusione
Discutiamo ora le implicazioni del model collapse sulle dinamiche di apprendimento alla base degli LLM. I poisoning attacks (attacchi hacker che mirano a inquinare i dati) a lungo termine sui modelli linguistici non sono nuovi. Per esempio, abbiamo assistito alla creazione di industrie di clic, contenuti e troll, una sorta di ‘modelli linguistici umani’, il cui compito è fuorviare i social network e gli algoritmi di ricerca. L’effetto negativo che questi attacchi hanno avuto sui risultati di ricerca ha portato a cambiamenti negli stessi algoritmi di ricerca: per esempio, Google ha declassato questi tipi di articoli, ponendo maggiore enfasi sui contenuti prodotti da fonti affidabili, come domini education, mentre DuckDuckGo li ha rimossi del tutto.
Ciò che cambia con l’arrivo degli LLM è la scala con cui tale inquinamento può avvenire, una volta automatizzato. Preservare la capacità degli LLM di modellare eventi a bassa probabilità è essenziale per l’equità delle loro previsioni: tali eventi sono spesso rilevanti per i gruppi emarginati. Anche gli eventi a bassa probabilità sono fondamentali per comprendere i sistemi complessi.
La nostra valutazione suggerisce un “vantaggio della prima mossa” quando si tratta di modelli di formazione come LLM. Nel nostro lavoro dimostriamo che l’addestramento su campioni di un altro modello generativo può indurre uno spostamento della distribuzione dei dati, che nel tempo causa il collasso del modello. Ciò a sua volta fa sì che il modello percepisca erroneamente il compito di apprendimento sottostante. Per garantire che quest’ultimo sia sostenuto per un lungo periodo di tempo, è necessario assicurarsi che sia preservato l’accesso alla fonte originale dei dati, e che quelli aggiuntivi non generati da LLM rimangano disponibili nel tempo. La necessità di distinguere i dati prodotti da LLM dagli altri dati, solleva interrogativi sulla provenienza dei contenuti scansionati da Internet: non è chiaro come quelli generati dagli LLM possano essere monitorati su larga scala. Un’opzione è il coordinamento a livello di comunità, per garantire che le diverse parti coinvolte nella creazione e distribuzione di LLM condividano le informazioni necessarie per risolvere gli aspetti relativi alla provenienza dei dati. In caso contrario, potrebbe diventare sempre più difficile addestrare le nuove versioni di LLM senza avere accesso ai dati che sono stati raccolti da Internet prima dell’adozione di massa di questa tecnologia, o senza avere accesso diretto ai dati generati dagli esseri umani su larga scala.
1) Cfr. https://www.lightbluetouchpaper.org/2023/06/06/will-gpt-models-choke-on-their-own-exhaust/
2) Cfr. https://arxiv.org/abs/2305.17493. Il paper è pubblicato sotto diritti Creative Commons. La traduzione dell’estratto è a cura di Paginauno